
До проведения необходимых для сертификации полетных испытаний, что является достаточно затратной процедурой, проводится анализ на основе физических моделей с учетом законов механики и аэродинамики для оценки недостающих данных по нагрузкам.
Задача сводится к автоматическому построению точных и робастных аппроксимационных моделей с использованием существующей базы данных по нагрузкам. Модели позволят автоматически прогнозировать величину статической и динамической нагрузок, действующих на детали вертолета, в зависимости от параметров полета, что позволит существенно сократить время и трудозатраты, требуемые для оценки недостающих данных.
Трудности
- База данных по нагрузкам, которая используется для построения аппроксимационных моделей с высокой предсказательной способностью для каждого конкретного типа вертолета, содержит огромный объем информации:
- 66 нагрузок (изгибающая нагрузка вала привода несущего винта, нагрузка на элементы втулки несущего винта и т. д) с двумя возможными вариациями относительно максимальной предписанной статической и динамической нагрузок;
- различные полетные конфигурации (всего 32 группы в зависимости от типа выполняемых маневров).
- Для каждого варианта количество точек в выборке неодинаково; это обстоятельство необходимо учитывать при выборе модели для обеспечения ее точности и робастности:
- 1,7% вариантов с 0 точками,
- 4,6% вариантов с 1 точкой,
- для 38% вариантов точек меньше, чем параметров,
- 32% вариантов имеют малое число точек,
- 23.7% вариантов имеют достаточное количество точек.
- Выбор наиболее подходящей для каждого случая модели должен осуществляться автоматически.
- Необходимо обеспечить возможность добавлять или изменять данные по вертолетам, типам нагрузок, видам маневров, а также другие параметры.
- Необходимо предупреждать конечного пользователя в случае, когда мы предполагаем, что прогноз может быть недостоверен.
Решение
Мы построили аппроксимационные модели трех различных типов с помощью широкого набора методов аппроксимации модуля GT Approx алгоритмического ядра pSeven Core, а именно:– аппроксимации полиномами невысокой размерности (RSM),
– аппроксимации на основе гауссовских процессов (GP),
– аппроксимации на основе нейронных сетей (HDA).
Техника аппроксимации и тип модели выбирались автоматически для каждого конкретного случая в зависимости от размера обучающей выборки.
Для вариантов с небольшим размером обучающей выборки применялись константные модели.
Выбор наиболее подходящей для каждого конкретного случая модели осуществлялся с использованием встроенного в pSeven Core функционала валидации качества моделей. Он позволяет осуществлять кросс-валидацию для оценки обобщающей способности модели в случаях, когда размер обучающей выборки ограничен. Такая проверка проводится с целью убедиться в способности модели предсказывать отклики в точках, не представленных в обучающей выборке. Кросс-валидация – это стандартный подход для оценки предсказательной способности модели: из обучающей выборки исключается один объект (элемент данных), оставшиеся данные используются для обучения модели, валидация модели осуществляется на основе исключенного объекта. Данную процедуру повторяют для всех элементов данных в выборке, тем самым получая среднюю предсказательную способность модели для данной обучающей выборки.
К моделям предъявлялись требования в отношении точности и робастности. В случаях, когда соблюсти указанные требования не представлялось возможным (к примеру, вследствие небольшого размера обучающей выборки), выбирались константные модели и формировался отчет об отсутствии достоверных результатов. Это позволило избежать некорректных прогнозов.
Результаты
Полученные прогнозные данные по статическим и динамическим нагрузкам сопоставили с результатами измерений, выполненных Airbus Helicopters для каждой группы в зависимости от типа выполняемых маневров. Мы сравнивали данные для всех полетных конфигураций, а также для отфильтрованных (только аппроксимационных моделей высокого качества). Мы разбили аппроксимационные модели на три группы в зависимости от качества: модели с высокой предсказательной способностью, модели с низкой предсказательной способностью и константные модели. Было обнаружено, что качество полученной модели напрямую зависит от изначальных характеристик обучающей выборки.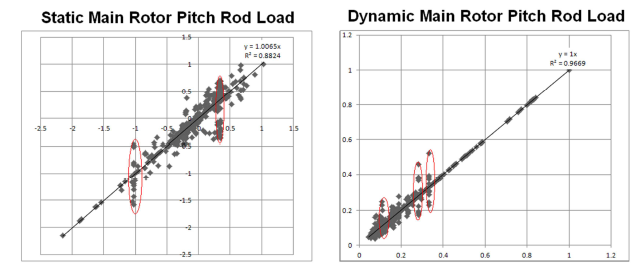
Сравнение прогнозных данных с результатами измерений (для всех полетных конфигураций)
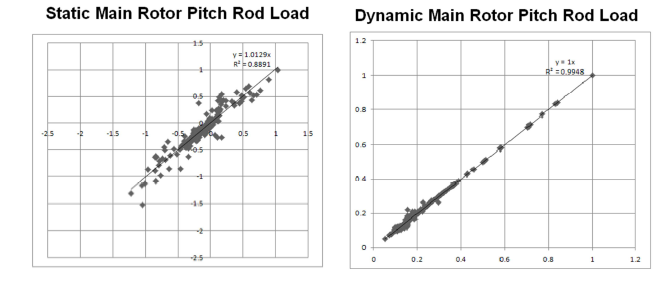
Сравнение прогнозных данных с результатами измерений (для отобранных конфигураций,
составляющих примерно 50% от всех полетных конфигураций по данному виду нагрузки)
По мнению заказчика, предложенный подход очень перспективен. С помощью аппроксимационных моделей можно с высокой точностью (< ±20%) спрогнозировать около 50% недостающих данных по нагрузкам, что позволит существенно сократить время и трудозатраты для оценки таких данных.