
Странно, столько слов отовсюду о цифровизации, и ни слова о том, чем она заканчивается. Чем заканчиваются большие данные, виртуальная реальность, генеративный дизайн? Как правило, – решением, которое принимает человек на основе моделей, существующих в его голове.
По-видимому, построение моделей в голове человека не считается большой проблемой, иначе в строительных вузах был бы предмет, знакомящий слушателей с основами семиотики и лингвистики. Что это даст? Примерно то же, что дает изучение русского языка в школе – ликвидацию неграмотности. Будущие строители поймут, что нет других инструментов, позволяющих достучаться до чужого мозга, кроме лингвистических, и научатся выражать свои мысли на профессиональном языке строителей – языке чертежей.
Взаимодействие между моделями
Есть три вида моделей.
- Субъективные модели – модели в голове человека.
- Цифровые модели – модели в памяти компьютера.
- Лингвистические модели – условные рисунки на бумаге или на экране компьютера – переходные мостики между субъективными и цифровыми моделями.
Рассмотрим варианты взаимодействия моделей.
Человек – человек
Обладатель субъективной модели создает и сохраняет лингвистическую модель в форме единого документа – комплекта чертежей. Данный процесс можно сравнить с написанием программы на языке высокого уровня. Получатель интерпретирует (компилирует) лингвистическую модель как единое целое. В итоге возникает понимание – субъективная модель в голове получателя. Таким образом, чертежи по своей сути являются алгоритмом построения субъективной модели, т.е. алгоритмом понимания.Человек – компьютер
Обладатель субъективной модели последовательно вводит команды в виде отдельных лингвистических предложений. Компьютер интерпретирует каждую команду в момент ее поступления. Как известно, по такой схеме работают программы-интерпретаторы. В итоге создается цифровая модель в памяти компьютера. Основное назначение цифровой модели – предоставление данных для обработки прикладным программам с целью получения новых данных.Компьютер – человек
По аналогии с вариантом «человек – человек» компьютер должен автоматически сформировать комплект чертежей. Проблема в том, что эта задача абсолютно не выполнима.Компьютер не может самостоятельно выбрать стратегию понимания, назначить шаги детализации, определить степень абстрагирования на каждом шаге, определить необходимое и достаточное количество видов, узлов, комментариев. Не может скомпоновать и озаглавить листы, определить последовательность просмотра, организовать систему ссылок на связанные документы внутри и вне проекта.
Проблему пытаются решить встраиванием элементов лингвистической модели (сохраняемых видов, аннотаций, рисунков и т. п.) в цифровую модель. Результат – гибридная модель, или BIM-модель – разновидность цифровых моделей. Считается, что гибридную модель можно использовать в качестве единой среды, надежной опоры для принятия решений всеми участниками строительства.
Проверим работоспособность этой идеи именно с точки зрения надежности. Допустим, создана единая модель (цифровой двойник, единый источник истины) одноэтажного производственного здания. Выполнены автоматические проверки, устранены коллизии. Следующий шаг – совещание экспертов с целью оценить качество проекта. Это одна из форм сотрудничества, которое, по общему мнению, должно осуществляться на основе «данных». Однако, данные – слишком широкое понятие; в зависимости от обстоятельств они могут иметь разное представление. Например, данные можно представить в виде таблиц конструктивных элементов, координат узлов, физических свойств и т. п.
Более глубокая обработка приводит данные к «человеко-читаемому» виду (рис. 1).
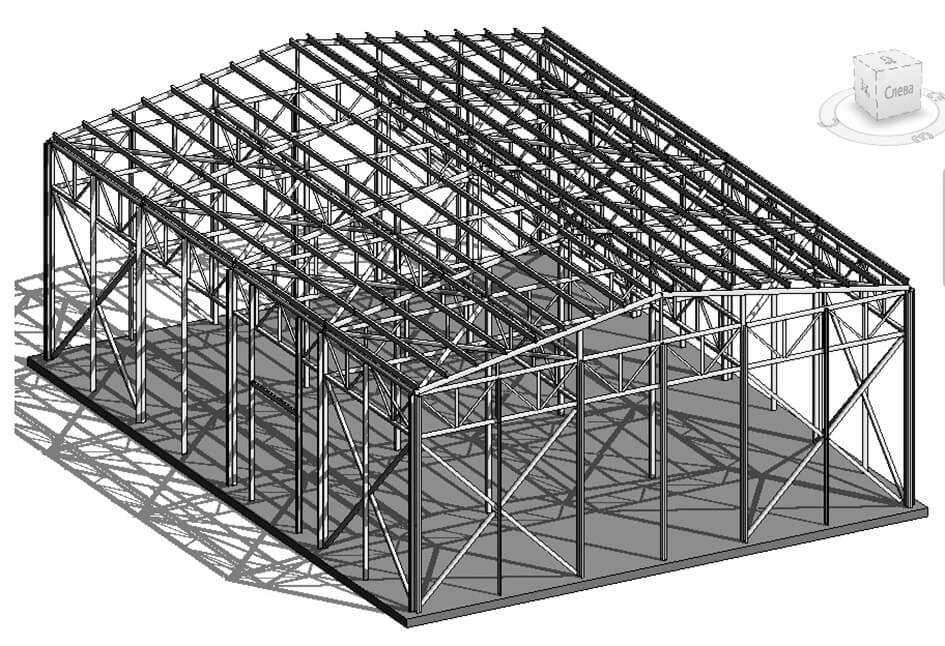
Рис. 1. Натуралистичное представление здания
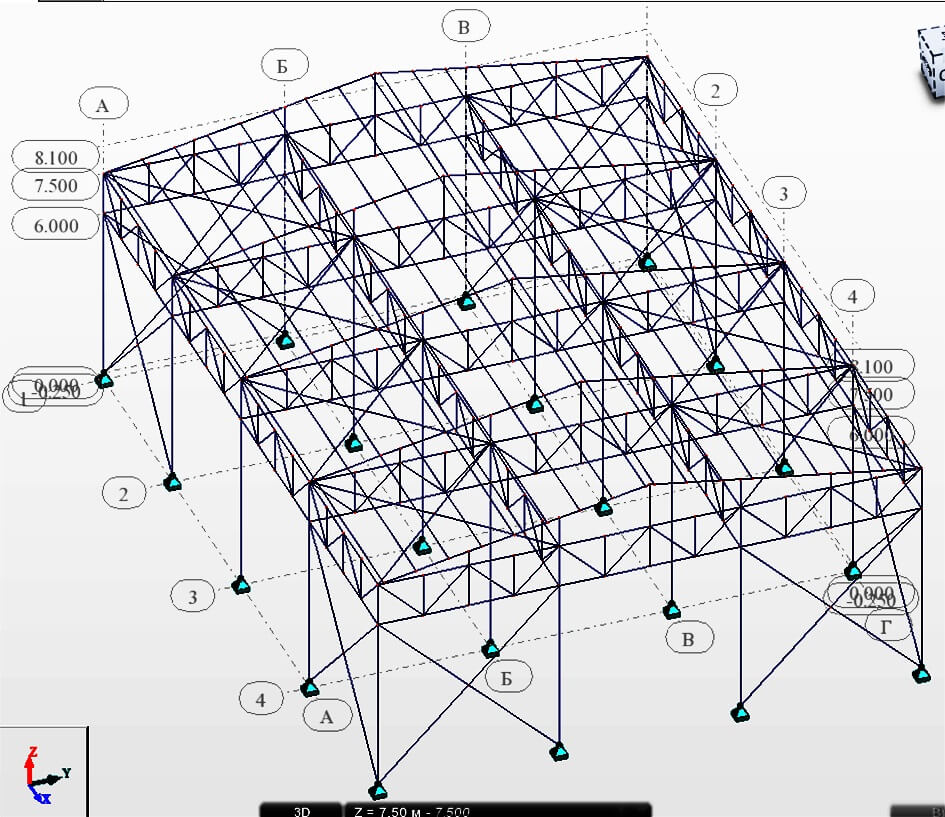
Рис. 2. Абстрагированное представление здания
Пример основан на реальном эпизоде, и можно сказать, что мнения экспертов разделились. Те, для кого представленная модель являлась единственным источником истины, оценили проект на отлично. Те, кто привлек дополнительные источники (в частности учебники по МК), оценили проект как непрофессиональный.
Что нужно понять? Я думаю, следующее.
- Сотрудничество и принятие решений возможны только на основе знаний (не данных!). Единственной формой представления знаний является лингвистическое (символьное) представление, проще говоря, чертежи.
- Исходным материалом для знаний являются данные, полученные в результате натурных (реальное строительство, лабораторные испытания) или компьютерных (цифровое моделирование) экспериментов. Знания рождаются в результате анализа данных человеком; автоматизировать этот процесс пока не удается. Знания надежны, если получены из нескольких независимых источников.
- Знания, полученные из любой модели, даже из самой «единой», – это ничтожная часть знаний, необходимых для принятия правильных решений.
Прибегать к моделированию (то есть к самодеятельному изготовлению знаний) нужно только в тех случаях, когда невозможно использовать имеющиеся, прошедшие проверку источники знаний – типовые серии, справочники, чертежи ранее осуществленных проектов. Понятно, что при таком подходе ни о каком едином источнике истины не может быть и речи. Зато может идти речь о реальном сокращении сроков и повышении качества проектов.
Компьютер – компьютер
Здесь все просто. Если две модели могут взаимодействовать друг с другом без участия человека, то их можно рассматривать как рассредоточенную единую модель.Если говорить о постепенном снижении роли и степени ответственности человека в строительном процессе, то такой тенденции я не вижу. Как и 40 лет назад, обязательный пункт любого лицензионного соглашения при покупке программного обеспечения – отказ от ответственности.
Извлечение чертежей из модели
Вне всякого сомнения, чертежи извлекаются из модели. Нужно только всегда уточнять: из какой модели и какого качества чертежи?Извлечение чертежей из цифровой модели
Ниже – фрагмент чертежа, автоматически созданный расчетной программой.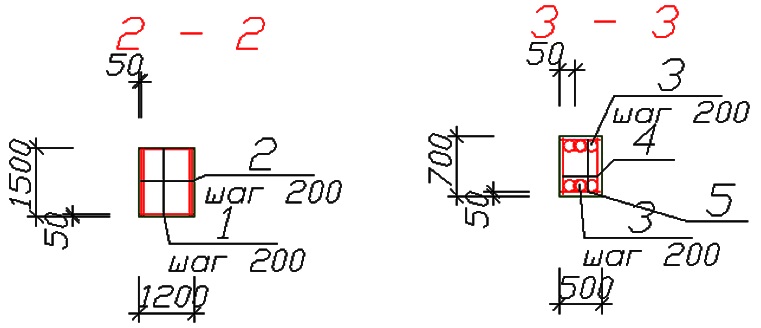
Рис. 3. Чертеж армирования столбчатого фундамента
Извлечение чертежей из гибридной модели
Разработчики BIM программ обещают автоматические чертежи отличного качества. Насколько это соответствует действительности? На рис. 4 представлен чертеж марки ТХ, вероятно, полученный из гибридной модели.
Рис. 4. Чертеж, извлеченный из гибридной модели
Нужно создать специальный чертеж, руководствуясь двумя ориентирами: для кого и для чего это нужно. В результате вместо рис. 4 должно получиться что-то похожее по стилю на рис. 5.
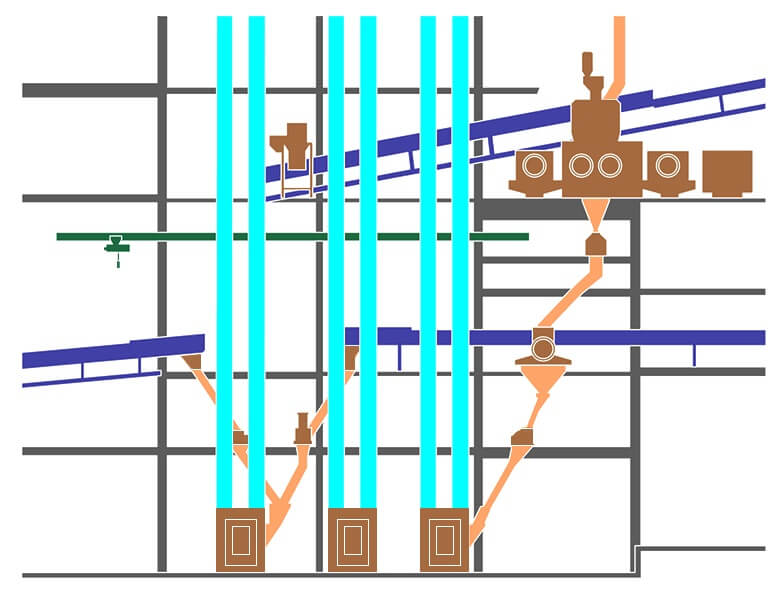
Рис. 5. Специализированный чертеж
Извлечение чертежей из субъективной модели
На рис. 6 представлен чертеж двухпутевого штрека. Примерно такие чертежи выпускали проектировщики в середине прошлого века.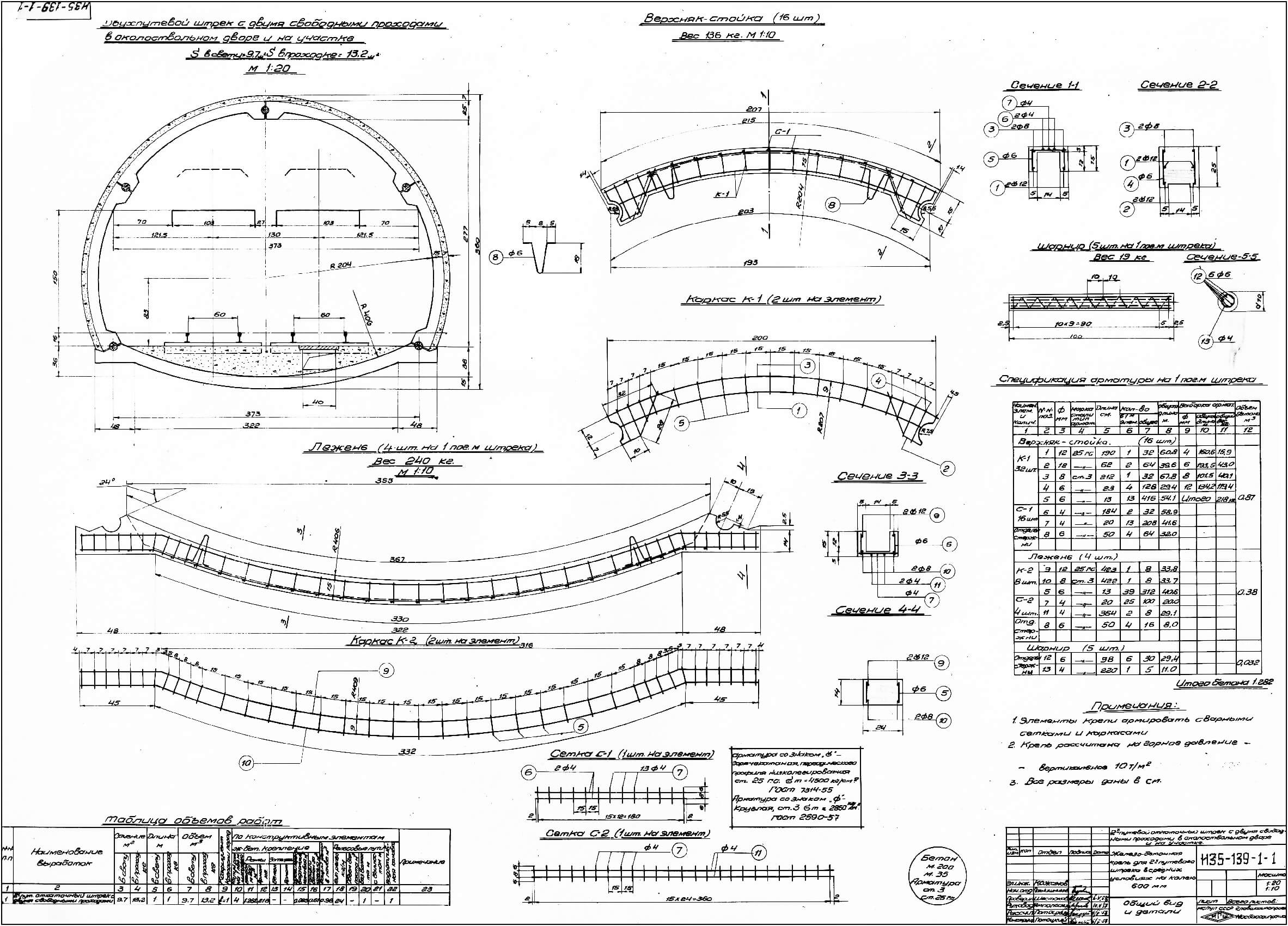
Рис. 6. Ручной чертеж старой школы
Другой барьер, связанный с чертежами, – неоднозначная интерпретация. Чертежи извлекаются автором из своей субъективной модели, и эти же чертежи являются алгоритмом построения субъективных моделей в головах других участников строительства. По идее, создаваемые модели должны быть копиями авторской модели. Однако не факт, что два разных человека, глядя в один и тот же чертеж, представляют себе одно и то же. В спорных случаях как узнать, кто прав?
Решение напрашивается. Должен быть эталон – цифровая компьютерная модель, созданная или авторизованная авторами чертежей. Эту модель можно создавать традиционным способом и включать в комплект поставки в дополнение к традиционным чертежам. Боюсь, однако, что судьба такой инновации повторит судьбу динозавров. Слишком громоздко, тяжеловесно, ресурсоемко для того, чтобы быть жизнеспособным.
Есть более красивое решение – интерпретируемые чертежи + компилятор чертежей. Решение абсолютно реализуемое. Действительно, нет никакой принципиальной разницы в алгоритмах построения модели с помощью чертежей и с помощью компьютерных команд. Как было замечено, это всего лишь разница в работе компилятора и интерпретатора.
Отличие лингвистической модели от цифровой
Любой инструмент, кроме его основного предназначения, должен еще «учить» пользователя правильной работе. Это значит, что за инструментом должна стоять идеология, которая диктует правильный путь использования и развития инструмента.Первое поколение 2D-редакторов – кульман. При всей ограниченности возможностей с точки зрения идеологии кульман был почти идеален. Он учитывал особенности зрительного восприятия, понимал незаменимость бумажного носителя, ставил приоритет ясности выше точности построений. Другими словами, кульман ориентировал проектировщика на создание именно чертежей – лингвистических моделей.
Второе поколение 2D-редакторов – поколение «автокада». История этого поколения – пример того, как ошибочная идеология заводит инструмент в тупик. Главная ошибка – непонимание сути чертежей. С самого начала был взят курс на создание не чертежей, а исходного материала для их извлечения. Проще говоря, вместо лингвистической модели «автокад» провоцирует пользователя строить цифровую 2D-модель. В итоге, в связи с появлением ARCHICAD и аналогичных программ, «автокад» считается отжившим инструментом, существующим только в силу привычки к нему пользователей.
На рис. 7 представлена цифровая 2D-модель судна на якорной стоянке. На рис. 8 – лингвистическая модель того же судна. Попробуем найти отличия.
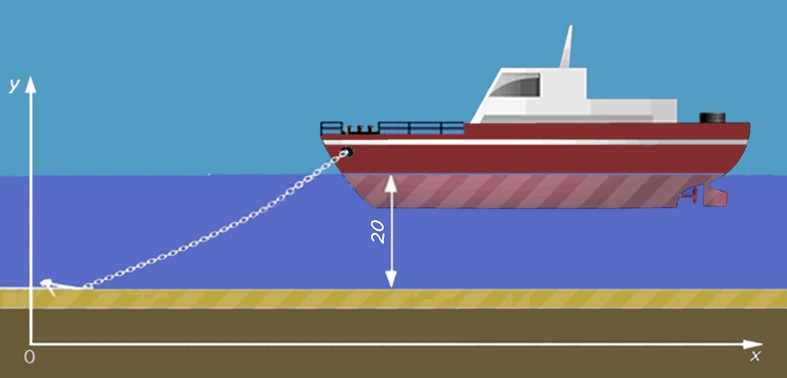
Рис. 7. Цифровая модель судна на якорной стоянке
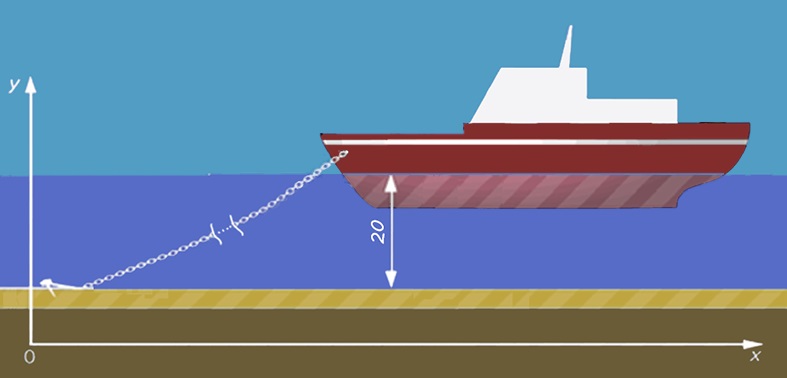
Рис. 8. Лингвистическая модель судна
На первый взгляд, «богатая данными» цифровая модель намного лучше лингвистической. Однако за точность надо платить. Предположим, исходные данные изменились, и встать на стоянку предстоит на глубине 30 м. В лингвистической модели просто исправляем цифру 20 на 30, и на этом редактирование заканчивается. В цифровой модели, чтобы оправдать слова о высочайшей точности, придется поднимать уровень моря, поднимать судно, сдвигать якорь, редактировать кривую провисания цепи.
Лингвистическую модель редактировать проще, но что делать, если нужно узнать больше деталей, например, о судне. Есть простой и эффективный метод – пошаговая детализация объектов. Маркируем судно и в спецификации объектов даем ссылку на деталировочные чертежи. Аналогичным образом решается вопрос о деталях якорной стоянки. В разделе примечаний даем ссылку на справочник, в котором в зависимости от глубины стоянки и характеристик судна приводятся все характеристики постановки судна на якорь.
Как видим, в лингвистических моделях, в отличие от цифровых, существует явная тенденция не дублировать то, что содержится во внешних источниках. Обе обсуждаемые выше модели используют одни и те же источники – справочники по устройству и управлению кораблем. Однако в первом случае на сведения из справочника дается ссылка; во втором – сведения копируются в модель.
Объяснение тут простое. Справочники, типовые серии, ГОСТы – это обычные лингвистические модели. Ссылки на них являются естественным продолжением чертежа. Ссылки из цифровой модели на лингвистическую – это ссылки «никуда», констатация факта, что цифровая модель на этом заканчивается и начинается лингвистическая.
И цифровая и лингвистическая модели не идеальны. Как избавиться от их недостатков и объединить преимущества? Я вижу выход в широком использовании возможностей машинной интерпретации лингвистических моделей. Это главный вызов следующего, третьего поколения 2D-редакторов.
Заключение
Предвижу вопрос: а где же описание нового редактора?Все темы, затронутые выше, – это попытка прояснить общую картину, выявить принципиальные проблемы. Когда картина ясна, детали реализации часто решаются сами собой. Как именно решаются – ноу-хау будущих разработчиков.