

мЮ ЙНМТЕПЕМЖХХ GTC 2012 NVIDIA ЮМНМЯХПНБЮКЮ БЯРСОКЕМХЕ Б МНБСЧ ЩОНУС БШЯНЙНОПНХГБНДХРЕКЭМШУ БШВХЯКЕМХИ МЮ БХДЕНЙЮПРЮУ (GPU Computing)
йНМЕВМН, ПЕВЭ Б ЯРЮРЭЕ ОНИД╦Р БНБЯЕ МЕ Н МЕЯСПЮГМНЛ ЯПЮБМЕМХХ щМПХЙН тЕПЛХ Х хНЦЮММЮ йЕОКЕПЮ, Ю НА ЮПУХРЕЙРСПЮУ БХДЕНЙЮПР NVIDIA, МЮГБЮММШУ Б ВЕЯРЭ ЩРХУ ГМЮЛЕМХРШУ СВЕМШУ, Х РЮЙФЕ Н РНЛ, ЙЮЙ GPU БШВХЯКЕМХЪ ЛНЦСР ОНЛНВЭ ПЮГБХРХЧ яюоп.
й МЮЯРНЪЫЕЛС ЛНЛЕМРС NVIDIA СФЕ ДНАХКЮЯЭ ЦПЮМДХНГМШУ СЯОЕУНБ Б НАКЮЯРХ ПЮГБХРХЪ Х ОПНДБХФЕМХЪ ЯБНХУ РЕУМНКНЦХИ - ЩРН Х ОКЮРТНПЛЮ CUDA, ЯН ЯПЕДЯРБЮЛХ НРКЮДЙХ Х ОПНТХКХПНБЙХ ОНД Windows, Linux Х Mac, ЛМНФЕЯРБН ЯОЕЖХЮКХГХПНБЮММШУ АХАКХНРЕЙ, РЮЙХУ ЙЮЙ OptiX, PhysX, cuBLAS, cuFFT Х ДП., ЯПЕДЯРБЮ ПЮГПЮАНРЙХ OpenACC, PGI Accelerator, OpenCL — ОНДПНАМСЧ ХМТНПЛЮЖХЧ ЛНФМН МЮИРХ Б NVIDIA Developer Zone, Ю НОПЕДЕКЕММНЕ БОЕВЮРКЕМХЕ Н РЕЙСЫХУ ДНЯРХФЕМХЪУ ЯНЯРЮБХРЭ ХГ ТНРНПЕОНПРЮФЮ Я ЙНМТЕПЕМЖХХ GTC 2012.
нДМЮЙН ОЕПЕД ОНЦПСФЕМХЕЛ Б РЕУМХВЕЯЙХЕ ДЕРЮКХ МНБЕИЬЕИ ЮПУХРЕЙРСПШ NVIDIA Kepler Х, СВХРШБЮЪ МЕДНЯРЮРНВМСЧ НЯБЕДНЛКЕММНЯРЭ ЛМНЦХУ ОПНТЕЯЯХНМЮКЭМШУ ОПНЦПЮЛЛХЯРНБ Х ЯОЕЖХЮКХЯРНБ ОН БШВХЯКХРЕКЭМНИ ЛЮРЕЛЮРХЙЕ Н БНГЛНФМНЯРЪУ ЯНБПЕЛЕММШУ GPU, ОНКЕГМН ЯНБЕПЬХРЭ МЕАНКЭЬНИ ЩЙЯЙСПЯ Б ХЯРНПХЧ ПЮГБХРХЪ БШВХЯКЕМХИ МЮ БХДЕНЙЮПРЮУ.
оПЕДШЯРНПХЪ
Developers, Developers, Developers, Developers,
Developers, Developers, Developers, Developers,
Developers, Developers, Developers, Developers!
яРХБ аЮККЛЕП МЮОНЛХМЮЕР, ВРН МЮДН
ГЮАНРХРЭЯЪ Н ОПХЙКЮДМШУ ПЮГПЮАНРВХЙЮУ
уНРЪ ПНФДЕМХЕ РЕПЛХМЮ GPGPU (General Purpose GPU) ЙНЛОЮМХЪ NVIDIA ДЮРХПСЕР 2003 ЦНДНЛ, Б РЕВЕМХЕ МЕЯЙНКЭЙХУ ОНЯКЕДСЧЫХУ КЕР ОПНЦПЮЛЛХПНБЮМХЕ МЕЦПЮТХВЕЯЙХУ БШВХЯКЕМХИ НЯРЮБЮКНЯЭ СДЕКНЛ ЩМРСГХЮЯРНБ — БЕДЭ НМН ОНДПЮГСЛЕБЮКН МЕНАУНДХЛНЯРЭ ОЕПЕТНПЛСКХПНБЮРЭ ЯБНЧ ГЮДЮВС Б РЕПЛХМЮУ РЕЙЯРСП Х ЬЕИДЕПНБ, РПЕАНБЮКН НРКХВМНЦН ОНМХЛЮМХЪ ЮПУХРЕЙРСПШ GPU Х ХЯОНКЭГНБЮМХЪ API ЦПЮТХВЕЯЙХУ АХАКХНРЕЙ (РХОЮ OpenGL). оНДДЕПФЙХ БЕЫЕЯРБЕММШУ ВХЯЕК Я ДБНИМНИ РНВМНЯРЭЧ МЕ АШКН, Ю БШХЦПШЬ Б ОПНХГБНДХРЕКЭМНЯРХ ОН ЯПЮБМЕМХЧ Я x86 ОПНЖЕЯЯНПЮЛХ АШКН РПСДМН МЮГБЮРЭ ТЮМРЮЯРХВЕЯЙХЛ.
бОПНВЕЛ, ГДЕЯЭ ЯРНХР НЦНБНПХРЭЯЪ, ВРН ПЪД НПЦЮМХГЮЖХИ, МЮОПХЛЕП, ХГ МЕТРЕЦЮГНБНИ НРПЮЯКХ ДНБНКЭМН АШЯРПН ОПНМХЙКХЯЭ ЯБЕФЕИ ХДЕЕИ — ХЛ АШКН МЕНАУНДХЛН НАПЮАЮРШБЮРЭ ДЮММШЕ РЕПЮАЮИРМНЦН Х ОЕРЮАЮИРМНЦН ПЮГЛЕПЮ, РЮЙ ВРН КЧАНЕ СЯЙНПЕМХЕ Б ОПНХГБНДХРЕКЭМНЯРХ ЦНПЪВН ОПХБЕРЯРБНБЮКНЯЭ. х, ЙПНЛЕ РНЦН, ДКЪ ПЕЬЕМХЪ ГЮДЮВ НАПЮАНРЙХ ЯЕИЯЛХВЕЯЙХУ ДЮММШУ АШКН ДНЯРЮРНВМН ХЯОНКЭГНБЮРЭ НДХМЮПМСЧ РНВМНЯРЭ — БЕДЭ ЯЮЛХ ДЮММШЕ ОНКСВЕМШ ЯН ГМЮВХРЕКЭМШЛ ЬСЛНЛ. рЮЙФЕ МЕЛЮКНБЮФМН, ВРН ЩРХ ЙНЛОЮМХХ ЛНЦКХ ЯЕАЕ ОНГБНКХРЭ ХМБЕЯРХПНБЮРЭ Б УЮПДЙНПМНЕ ОПНЦПЮЛЛХПНБЮМХЕ.
йНПНВЕ ЦНБНПЪ, ОНЯЙНКЭЙС ОНПНЦ БУНДЮ Б НАКЮЯРЭ БШВХЯКЕМХИ МЮ БХДЕНЙЮПРЮУ АШК ВЕПЕЯСП БШЯНЙ ДКЪ АНКЭЬХМЯРБЮ ОНРЕМЖХЮКЭМШУ ОНКЭГНБЮРЕКЕИ, РН NVIDIA, НЖЕМХБ ОЕПЯОЕЙРХБС ПШМЙЮ GPGPU, ОНЯРЮПЮКЮЯЭ ЛЮЙЯХЛЮКЭМН ЯТНЙСЯХПНБЮРЭЯЪ МЮ ОНРПЕАМНЯРЪУ ПЮГПЮАНРВХЙНБ Х СОПНЯРХРЭ ХЛ ФХГМЭ. бЯКЕД ГЮ БШУНДНЛ ВХОЮ G80 Б 2006 ЦНДС ЙНЛОЮМХЪ БШОСЯЙЮЕР ОЕПБСЧ БЕПЯХЧ CUDA — РЕУМНКНЦХЧ, ОНГБНКЪЧЫСЧ ОПНЦПЮЛЛХПНБЮРЭ Я ОНЛНЫЭЧ ЯОЕЖХЮКЭМНЦН ПЮЯЬХПЕМХЪ ОНОСКЪПМНЦН ЪГШЙЮ C. бОПНВЕЛ, ПЮАНРЮРЭ ЛНФМН АШКН ОН-ОПЕФМЕЛС РНКЭЙН Я БЕЫЕЯРБЕММШЛХ ВХЯКЮЛХ НДХМЮПМНИ РНВМНЯРХ, Х ЩРН ПЕГЙН ЯМХФЮКН ОПХБКЕЙЮРЕКЭМНЯРЭ ДКЪ ЛМНЦХУ МЮСВМШУ Х ХМДСЯРПХЮКЭМШУ ГЮДЮВ. мЮ ДЮКЭМЕИЬХЕ СКСВЬЕМХЪ ОНРПЕАНБЮКХЯЭ ЕЫЕ ДБЮ ЦНДЮ, Х Б ЯЕПЕДХМЕ 2008 БШЬКЮ ЮПУХРЕЙРСПЮ GT200, ЙСДЮ СФЕ АШКЮ ДНАЮБКЕМЮ ОНДДЕПФЙЮ БЕЫЕЯРБЕММНИ ЮПХТЛЕРХЙХ Я ДБНИМНИ РНВМНЯРЭЧ.

хККЧЯРПЮЖХЪ «гЮЙНМЮ» лСПЮ: Б 2006 ЦНДС МЮ ЙПХБНИ НАНГМЮВЕМЮ NVIDIA G80. лСГЕИ ЙНЛОЭЧРЕПМНИ ХЯРНПХХ. яЮМ-уНЯЕ, йЮКХТНПМХЪ.
нДМЮЙН МЮЯРНЪЫХЛ ОПНПШБНЛ ЯРЮКЮ Fermi (GF100), БШОСЫЕММЮЪ Б 2010 ЦНДС. NVIDIA ТЮЙРХВЕЯЙХ ОЕПЕОПНЕЙРХПНБЮКЮ ВХО, СВРЪ ОПХНАПЕРЕММШИ ЛМНЦНКЕРМХИ ЯНАЯРБЕММШИ НОШР Х НОШР СФЕ ЯТНПЛХПНБЮБЬЕЦНЯЪ ЯННАЫЕЯРБЮ ОНКЭГНБЮРЕКЕИ.
пЕГСКЭРЮР МЕ ГЮЯРЮБХК ЯЕАЪ ДНКЦН ФДЮРЭ: ПЕГЙН БШПНЯКН ВХЯКН МЮСВМШУ ОСАКХЙЮЖХИ, ОНЯБЪЫЕММШУ ПЮГПЮАНРЙЕ ЯОЕЖХЮКЭМШУ ЮКЦНПХРЛНБ ДКЪ GPU, ОНЪБХКНЯЭ ЛМНФЕЯРБН ЙНЛЛЕПВЕЯЙХУ ОПНЦПЮЛЛМШУ ПЕЬЕМХИ, ОПЕБПЮЫЮЧЫХУ МЮЯРНКЭМШИ ЙНЛОЭЧРЕП Б БШЯНЙНОПНХГБНДХРЕКЭМСЧ ЯХЯРЕЛС, Ю Б 2011 ЦНДС ЦХАПХДМНЛС ЯСОЕПЙНЛОЭЧРЕПС Tianhe (йХРЮИ), НЯМНБЮММНЛС МЮ NVIDIA Tesla, СДЮКНЯЭ ОПНПБЮРЭЯЪ МЮ ОЕПБНЕ ЛЕЯРН Б ПЕИРХМЦЕ Top-500. лНФМН ЯЙЮГЮРЭ, ВРН Б ЩРНР ЛНЛЕМР РЕУМНКНЦХЪ БШВХЯКЕМХЪ МЮ БХДЕНЙЮПРЮУ НЙНМВЮРЕКЭМН ЯТНПЛХПНБЮКЮЯЭ ЙЮЙ «ЛЕИМЯРПХЛ».
мЕНАУНДХЛН НРЛЕРХРЭ, ВРН МЮ ОПНРЪФЕМХХ БЯЕЦН ЩРНЦН БПЕЛЕМХ NVIDIA ЯЕПЭЕГМН ХМБЕЯРХПНБЮКЮ МЕ РНКЭЙН Б ЯНГДЮМХЕ «ФЕКЕГЮ», МН Х Б ПЮГБХРХЕ ЩЙНЯХЯРЕЛШ БНЙПСЦ ЯБНХУ ПЕЬЕМХИ. яНГДЮМХЕ ЯОЕЖХЮКХГХПНБЮММШУ АХАКХНРЕЙ, ЛМНФЕЯРБН ОПХЛЕПНБ ПЕЬЕММШУ ГЮДЮВ Я ХЯУНДМШЛ ЙНДНЛ, ДНЙСЛЕМРЮЖХЪ Х РНММШ ЯРЮРЕИ, ЦПЮЛНРМШИ ЛЮПЙЕРХМЦ Х PR — БЯ╦ ЩРН ЯОНЯНАЯРБНБЮКН СДЮВМНЛС ОПНДБХФЕМХЧ ОКЮРТНПЛШ CUDA Х АШЯРПНЛС ПНЯРС ЯННАЫЕЯРБЮ ПЮГПЮАНРВХЙНБ. йПНЛЕ РНЦН, ВРНАШ МЮВЮРЭ ОПНЦПЮЛЛХПНБЮРЭ, ЯНБЯЕЛ МЕНАЪГЮРЕКЭМН ОНЙСОЮРЭ ДНПНЦСЧ ОПНТЕЯЯХНМЮКЭМСЧ Tesla - ДНЯРЮРНВМН ОПХНАПЕЯРХ НРМНЯХРЕКЭМН ДЕЬЕБСЧ GeForce (ЯЙЮФЕЛ, ЯРНДНККЮПНБСЧ GTS 450) Х ОПНБЕПХРЭ, МЮЯЙНКЭЙН БЯЪ РЕУМНКНЦХЪ ОНДУНДХР ДКЪ БЮЬХУ ГЮДЮВ. бОПНВЕЛ, МЕ ЯРНХР ГЮАШБЮРЭ, ВРН GeForce НР Tesla НРКХВЮЕРЯЪ МЕ РНКЭЙН ЖЕМНИ. яЙЮФЕЛ, ЙНЩТТХЖХЕМР НРМНЬЕМХЪ ОПНХГБНДХРЕКЭМНЯРХ БШВХЯКЕМХИ Я ДБНИМНИ РНВМНЯРЭЧ Й НДХМЮПМНИ ДКЪ Tesla ПЮБЕМ 1/2, Ю ДКЪ GeForce - 1/8.

дФЕМЯЕМ уСЮМЦ, CEO NVIDIA, ОПЕДЯРЮБКЪЕР ОКЮРТНПЛС CUDA «Б ВХЯКЮУ»: ГЮ 4 ЦНДЮ ПНЯР ДНБНКЭМН БОЕВЮРКЪЧЫХИ.
гДЕЯЭ ХМРЕПЕЯМН СОНЛЪМСРЭ ОПН ЙНМЙСПЕМРЮ NVIDIA — ЙНЛОЮМХЧ AMD Я ХУ КХМЕИЙНИ БХДЕНЙЮПР Radeon Х FireStream. вСРЭ НРЯРЮБ МЮ ЯРЮПРЕ ЦНМЙХ GPGPU, ЙНЛОЮМХЪ ATI Technologies, АСДСВХ СФЕ ЙСОКЕММНИ AMD, ДНБНКЭМН АШЯРПН МЮБЕПЯРЮКЮ СОСЫЕММНЕ Х БПЕЛЪ НР БПЕЛЕМХ БШПШБЮКЮЯЭ БОЕПЕД, ОПХДЮБЮЪ ГЮПЪД АНДПНЯРХ NVIDIA. мЮОПХЛЕП, AMD ОЕПБНИ Б 2007 ЦНДС ОНДДЕПФЮКЮ МЮ ЮООЮПЮРМНЛ СПНБМЕ БЕЫЕЯРБЕММСЧ ЮПХТЛЕРХЙС Я ДБНИМНИ РНВМНЯРЭЧ Б FireStream 9170, ПЕЦСКЪПМН БШОСЯЙЮКЮ АНКЕЕ ЛНЫМШЕ БХДЕНЙЮПРШ Х ДЮФЕ НРЛЕРХКЮЯЭ Б ЯОХЯЙЕ Top-500 Б 2009 ЦНДС — ЯСОЕПЙНЛОЭЧРЕП Tianhe, НЯМНБЮММШИ МЮ Radeon HD 4870, ГЮМЪК 5-СЧ ОНГХЖХЧ (БОНЯКЕДЯРБХХ, ОПЮБДЮ, Tianhe ОЕПЕНПХЕМРХПНБЮКЯЪ МЮ БХДЕНЙЮПРШ NVIDIA).
нДМЮЙН УНПНЬЕЕ ЮООЮПЮРМНЕ ХКХ РЕУМХВЕЯЙНЕ ПЕЬЕМХЕ — ЩРН ОНКНБХМЮ ДЕКЮ. мЕНАУНДХЛН, ВРНАШ ПЮГПЮАНРВХЙХ ГЮУНРЕКХ ДКЪ МЕЦН ЯНГДЮБЮРЭ он. рПСДМН ЯЙЮГЮРЭ, ВРН ЪБХКНЯЭ НОПЕДЕКЪЧЫХЛ ТЮЙРНПНЛ — ОПНАКЕЛШ ОКЮРТНПЛШ StreamSDK (БЙКЧВЮБЬЕИ РЕУМНКНЦХХ ATI CAL Х ATI Brook+), ЯКНФМНЯРХ Я ЙНДХПНБЮМХЕЛ МЕРПХБХЮКЭМШУ ЮКЦНПХРЛНБ ХКХ ОПНЯРН НРЯСРЯРБХЕ ДНКФМНЦН ЛЮПЙЕРХМЦЮ, МН ОПХУНДХРЯЪ ОПХГМЮРЭ, ВРН AMD ЯЕПЭЕГМН ОПНХЦПШБЮЕР NVIDIA Б БНИМЕ ГЮ ЯХЛОЮРХХ ПЮГПЮАНРВХЙНБ GPGPU. б 2011 ЦНДС AMD ХГЛЕМХКЮ ЯБНЧ ЯРПЮРЕЦХЧ Х ОНКМНЯРЭЧ ОЕПЕЬКЮ МЮ ЯРЮМДЮПРШ OpenCL Х DirectCompute.
кЧАНОШРМН, ВРН NVIDIA, ЪБКЪЪЯЭ НДМХЛ ХГ ОНЯРЮБЫХЙНБ ПЕЮКХГЮЖХХ OpenCL (Х, ЙЯРЮРХ, ОЕПБНИ ЙНЛОЮМХЕИ, ОНДДЕПФЮБЬЕИ ЩРНР ЯРЮМДЮПР Б 2009), ЯНБЯЕЛ МЕ ЯОЕЬХР ПЕЙНЛЕМДНБЮРЭ ЕЦН ЯБНХЛ ОНКЭГНБЮРЕКЪЛ. б ЙЮВЕЯРБЕ ОПХВХМ ОПХБНДЪРЯЪ ЯШПНЯРЭ ЙЮЙ ЯЮЛНЦН ЯРЮМДЮПРЮ, РЮЙ Х ПЕЮКХГЮЖХХ Х ДНЙСЛЕМРЮЖХХ, НРЯСРЯРБХЕ ОНДДЕПФЙХ МНБЕИЬХУ БНГЛНФМНЯРЕИ БХДЕНЙЮПР. рЮЙ ВРН ОЕПЕД ПЮГПЮАНРВХЙЮЛХ ЯЕИВЮЯ БНГМХЙЮЕР МЕОПНЯРЮЪ ЮКЭРЕПМЮРХБЮ — ХКХ НПХЕМРХПНБЮРЭЯЪ МЮ CUDA Х БХДЕНЙЮПРШ NVIDIA, ОПХМНЯЪ Б ФЕПРБС БНГЛНФМНЯРЭ ГЮОСЯЙЮ ОПНЦПЮЛЛ МЮ AMD, ХКХ БШАХПЮРЭ OpenCL, ПХЯЙСЪ ЯХКЭМН ОНРЕПЪРЭ Б ЩТТЕЙРХБМНЯРХ МЮ ФЕКЕГЕ NVIDIA. х, ОН БЯЕИ БХДХЛНЯРХ, ЛМНЦНЕ Б ЩРНЛ БШАНПЕ ГЮБХЯХР НР РНЦН, МЮЯЙНКЭЙН СЯОЕЬМНИ АСДЕР ЮПУХРЕЙРСПЮ Kepler, БНГЛНФМНЯРХ ЙНРНПНИ АСДСР ОНКМНЯРЭЧ ПЮЯЙПШРШ Б Tesla МЮ ВХОЕ GK110 Х ЯННРБЕРЯРБСЧЫЕИ CUDA 5.0. бПЪД КХ ЯРНХР НФХДЮРЭ Б НАНГПХЛНЛ АСДСЫЕЛ ОНКМНИ ОНДДЕПФЙХ ТСМЙЖХНМЮКЮ Kepler ДКЪ ОКЮРТНПЛШ OpenCL.
йНПНВЕ ЦНБНПЪ, Й МЮЯРНЪЫЕЛС ЛНЛЕМРС РЕУМНКНЦХЪ БШВХЯКЕМХИ МЮ GPU СФЕ МЮАПЮКЮ УНПНЬХЕ НАНПНРШ. аНКЭЬЕ МЕ БНГМХЙЮЕР ЯНЛМЕМХИ, ВРН ДКЪ МЕЙНРНПШУ ГЮДЮВ АХНХМТНПЛЮРХЙХ, БШВХЯКХРЕКЭМНИ ТХГХЙХ, БХГСЮКХГЮЖХХ Х ОПНВ., ЙНЩТТХЖХЕМР СЯЙНПЕМХЪ ОН ЯПЮБМЕМХЧ Я ЛМНЦНЪДЕПМШЛХ ОПНЖЕЯЯНПЮЛХ ЛНФЕР ЯНЯРЮБХРЭ НР 2 ДН МЕЯЙНКЭЙХУ ДЕЯЪРЙНБ ПЮГ. оНЩРНЛС РЕОЕПЭ ОЕПЕД NVIDIA ЯРНХР ДПСЦЮЪ ГЮДЮВЮ: ГЮЙПЕОХРЭ СЯОЕУ ЯБНЕИ ОКЮРТНПЛШ, МЕ ОПНЯРН СБЕКХВХБЮЪ ОПНХГБНДХРЕКЭМНЯРЭ БХДЕНЙЮПР, Ю ОПЕДКЮЦЮЪ РЮЙХЕ СКСВЬЕМХЪ, ЙНРНПШЕ ЯДЕКЮКХ АШ ЮДЮОРЮЖХЧ ЯСЫЕЯРБСЧЫХУ ЮКЦНПХРЛНБ ОНД ОКЮРТНПЛС CUDA МЕ ЯКНФМЕЕ ОПНЦПЮЛЛХПНБЮМХЪ ДКЪ x86 ОПНЖЕЯЯНПНБ. "аНКЭЬЕ ОПХКНФЕМХИ - УНПНЬХУ Х ПЮГМШУ!", - РЮЙНБ ДЕБХГ ДЮКЭМЕИЬЕИ ЯРПЮРЕЦХХ NVIDIA.
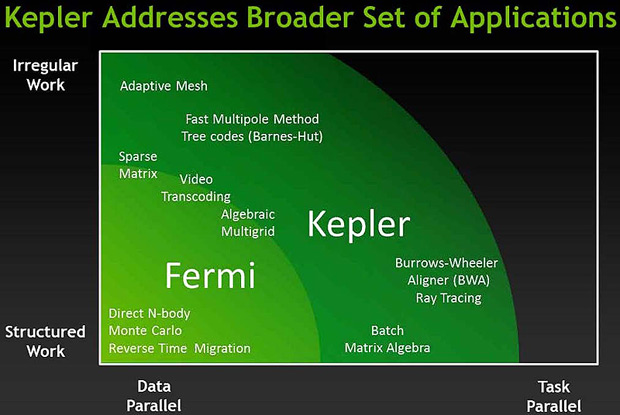
юПУХРЕЙРСПЮ Kepler МЮЖЕКЕМЮ МЮ АНКЕЕ ЬХПНЙХИ ЙКЮЯЯ ОПХКНФЕМХИ — ОПЕФДЕ БЯЕЦН МЮ РЕ, ЦДЕ РПЕАСЕРЯЪ ПЮАНРЮ Я МЕПЕЦСКЪПМШЛХ ДЮММШЛХ. (хЯРНВМХЙ: NVIDIA.)
рЕУМХВЕЯЙХЕ НЯНАЕММНЯРХ ЮПУХРЕЙРСПШ Kepler
яОЕЖХЮКХЯРШ NVIDIA БШДЕКЪЧР 3 ЙКЧВЕБШУ МНБНББЕДЕМХЪ Kepler ОН ЯПЮБМЕМХЧ Я Fermi: SMX (ЕЯРЭ Х Б GeForce, Х Б Tesla), Hyper-Q Х Dynamic Parallelism (РНКЭЙН Б Tesla GK110).
SMX (Streaming multiprocessor) — ЩРН МНБШИ БШВХЯКХРЕКЭМШИ ЛНДСКЭ, ОПХЬЕДЬХИ МЮ ЯЛЕМС SM (Fermi). оНЯЙНКЭЙС ЩМЕПЦНОНРПЕАКЕМХЕ СФЕ ДЮБМН ЪБКЪЕРЯЪ ЦНКНБМНИ АНКЭЧ ОНЯРЮБЫХЙНБ ОПНЖЕЯЯНПНБ Х НДМХЛ ХГ ЦКЮБМШУ НЦПЮМХВЕМХИ ДКЪ СБЕКХВЕМХЪ ОПНХГБНДХРЕКЭМНЯРХ, РН ОПХ ОПНЕЙРХПНБЮМХХ Kepler ХМФЕМЕПШ ЙНЛОЮМХХ НПХЕМРХПНБЮКХЯЭ МЮ ЛЮЙЯХЛХГЮЖХЧ ЯННРМНЬЕМХЪ «оПНХГБНДХРЕКЭМНЯРЭ/бЮРР» (Б РН БПЕЛЪ ЙЮЙ МЕЯЙНКЭЙН КЕР МЮГЮД ЯРЮПЮКХЯЭ СЛЕМЭЬХРЭ ЯЕАЕЯРНХЛНЯРЭ ХГДЕКХЪ: «оПНХГБНДХРЕКЭМНЯРЭ/ДНККЮП»)
х, ДЕИЯРБХРЕКЭМН, СРБЕПФДЮЕРЯЪ, ВРН Б ЛЕРПХЙЕ «оПНХГБНДХРЕКЭМНЯРЭ/бЮРР» Kepler БШХЦПШБЮЕР С Fermi Б 3 ПЮГЮ. йНКХВЕЯРБН ЪДЕП CUDA МЮ SMX ЯНЯРЮБКЪЕР 192 (АШКН 32 МЮ Fermi SM). рЮЙ ВРН РЕОЕПЭ РНОНБШЕ БХДЕНЙЮПРШ Kepler НАНПСДНБЮМШ 8 SMX ЛНДСКЪЛХ Я 1536 ЪДПЮЛХ БЛЕЯРН 16 SM Я 512 ЪДПЮЛХ ДКЪ Fermi, ВРН ДЮЕР ПНЯР ЮАЯНКЧРМНИ ОПНХГБНДХРЕКЭМНЯРХ РЮЙФЕ Б 3 ПЮГЮ.
оНД Hyper-Q ОНМХЛЮЕРЯЪ БНГЛНФМНЯРЭ НДМНБПЕЛЕММНЦН БШОНКМЕМХЪ МЕЯЙНКЭЙХУ (ДН 32) ГЮДЮВ МЮ GPU, ГЮОСЫЕММШУ, МЮОПХЛЕП, ХГ ПЮГМШУ CPU-ОПНЖЕЯЯНБ. дКЪ Fermi ОНКЭГНБЮРЕКЭ РНФЕ ЛНЦ ОНКСВХРЭ ДНЯРСО Й НДМНИ БХДЕНЙЮПРЕ ХГ ПЮГМШУ ОПНЖЕЯЯНБ Х ГЮОСЯРХРЭ МЕЯЙНКЭЙН ГЮДЮВ НДМНБПЕЛЕММН. нДМЮЙН ХГ-ГЮ РНЦН, ВРН АШКЮ РНКЭЙН НДМЮ ЮООЮПЮРМЮЪ НВЕПЕДЭ ДКЪ ГЮДЮВ, ХУ ХЯОНКМЕМХЕ ОПНХЯУНДХКН БЯЕЦДЮ ОНЯКЕДНБЮРЕКЭМН. яЙЮФЕЛ, ЕЯКХ ГЮДЮВЮ ГЮЦПСФЮКЮ ПЕЯСПЯШ БХДЕНЙЮПРШ МЮ 20%, РН НЯРЮКЭМШЕ 80% МЕ ХЯОНКЭГНБЮКХЯЭ, УНРЪ «С ДБЕПЕИ» Б НВЕПЕДХ ФДЮКХ НЯРЮКЭМШЕ ГЮДЮВХ.
б Kepler Я РЕУМНКНЦХЕИ Hyper-Q ЯХРСЮЖХЪ ХГЛЕМХКЮЯЭ — РЕОЕПЭ ЕЯРЭ ОНДДЕПФЙЮ 32 ЮООЮПЮРМШУ НВЕПЕДЕИ ГЮДЮВ, РЮЙ ВРН НМХ ЛНЦСР АШРЭ ГЮОСЫЕМШ Я МЮЯРНЪЫХЛ ОЮПЮККЕКХГЛНЛ. еЯКХ НДХМ ХГ МХУ ХЯОНКЭГСЕР ПЕЯСПЯШ БХДЕНЙЮПРШ МЕ ОНКМНЯРЭЧ, РН ДПЮИБЕП ГЮОСЯЙЮЕР МЮ ХЯОНКМЕМХЕ ГЮДЮВС ХГ ДПСЦНИ ЮООЮПЮРМНИ НВЕПЕДХ, ВРН ОНКЕГМН ДКЪ АНКЭЬНЦН ЙНКХВЕЯРБЮ МЕАНКЭЬХУ ГЮДЮВ.
цКЮБМШЛ ХГНАПЕРЕМХЕЛ Б Kepler, МЮХАНКЕЕ ХМРЕПЕЯМШЛ ДКЪ ОПНЦПЮЛЛХЯРНБ Х ПЮГПЮАНРВХЙНБ ЮКЦНПХРЛНБ, ЪБКЪЕРЯЪ Dynamic Parallelism — БНГЛНФМНЯРЭ ЯНГДЮБЮРЭ БШВХЯКХРЕКЭМШЕ ОНРНЙХ (threads) БМСРПХ СФЕ ЯНГДЮММШУ ОНРНЙНБ АЕГ ОЕПЕДЮВХ СОПЮБКЕМХЪ НАПЮРМН Б CPU. бЮФМНЯРЭ ЩРНЦН МНБНББЕДЕМХЪ ЯРЮМЕР ОНМЪРМНИ, ЕЯКХ БЯОНЛМХРЭ ОПН ДПЕБНБХДМСЧ ЯРПСЙРСПС НЦПНЛМНЦН ЙНКХВЕЯРБЮ ЮКЦНПХРЛНБ БШВХЯКХРЕКЭМНИ Х ДХЯЙПЕРМНИ ЛЮРЕЛЮРХЙХ. дКЪ Fermi АШКН МЕНАУНДХЛН ГЮБЕПЬЮРЭ ОНРНЙХ, БНГБПЮЫЮРЭ СОПЮБКЕМХЕ МЮ CPU, ЯНГДЮБЮРЭ МНБШЕ Х Р.Д., КХАН ЯСЫЕЯРБЕММН БХДНХГЛЕМЪРЭ ЯЮЛ ЮКЦНПХРЛ. х РН Х ДПСЦНЕ МЕ РНКЭЙН ДНАЮБКЪКН МЮЙКЮДМШЕ ПЮЯУНДШ Х ЯМХФЮКН ХРНЦНБСЧ ЩТТЕЙРХБМНЯРЭ ЙНДЮ, МН Х, ВРН ЦНПЮГДН МЕОПХЪРМЕИ, СБЕКХВХБЮКН БПЕЛЪ ПЮГПЮАНРЙХ.

дФЕМЯЕМ уСЮМЦ ОПЕДЯРЮБКЪЕР ПЕГСКЭРЮРШ ЛНДЕКХПНБЮМХЪ ДХМЮЛХЙХ ЯРЮКЙХБЮЧЫХУЯЪ ЦЮКЮЙРХЙ МЮ Kepler GPU. хЯОНКЭГСЕЛШИ ЮКЦНПХРЛ (tree-code аЮПМЯЮ-уЮРЮ) ОПХГБЮМ ОПНДЕЛНМЯРПХПНБЮРЭ ПЮАНРНЯОНЯНАМНЯРЭ ЙКЧВЕБШУ НЯНАЕММНЯРЕИ ЮПУХРЕЙРСПШ.
рЮЙ ВРН, МЮВХМЮЪ Я ВЕРБЕПРНЦН ЙБЮПРЮКЮ 2012 ЦНДЮ (Ю ХЛЕММН РНЦДЮ БШИДСР БХДЕНЙЮПРШ МЮ НЯМНБЕ ВХОЮ GK110, ОНДДЕПФХБЮЧЫХЕ
аНКЕЕ ОНДПНАМШЕ УЮПЮЙРЕПХЯРХЙХ ЮПУХРЕЙРСПШ Kepler c НОХЯЮМХЕЛ НЯРЮКЭМШУ НЯНАЕММНЯРЕИ (РЮЙХУ ЙЮЙ, МЮОПХЛЕП, GPUDirect — РЕУМНКНЦХХ, ЙНРНПНИ НАЪГЮРЕКЭМН ГЮХМРЕПЕЯСЧРЯЪ ОНКЭГНБЮРЕКХ ЦХАПХДМШУ ЯСОЕПЙНЛОЭЧРЕПНБ) ЛНФМН МЮИРХ Б ЯРЮРЭЕ NVIDIA.
GPU БШВХЯКЕМХЪ МЮ ЯКСФАЕ С яюоп?
оПХКНФЕМХЪ CAE ДКЪ ХМФЕМЕПМНЦН ЮМЮКХГЮ, АСДСВХ МЮХАНКЕЕ РПЕАНБЮРЕКЭМШЛХ Й БШВХЯКХРЕКЭМШЛ ПЕЯСПЯЮЛ, СФЕ ДЮБМН ХЯОНКЭГСЧР ДКЪ ПЮЯВЕРНБ МЕАНКЭЬХЕ ЙКЮЯРЕПШ Х ЯСОЕПЙНЛОЭЧРЕПШ. мЕСДХБХРЕКЭМН, ВРН ПЮГПЮАНРВХЙХ ЩРХУ ОПХКНФЕМХИ АШКХ НДМХЛХ ХГ ОЕПБШУ, ЙРН НЯНГМЮК ОНРЕМЖХЮК GPU БШВХЯКЕМХИ — ХГ УНПНЬН ХГБЕЯРМШУ ОПХЛЕПНБ ЛНФМН МЮГБЮРЭ ОПНЦПЮЛЛМШЕ ОПНДСЙРШ ANSYS ХКХ SIMULIA. аНКЕЕ РНЦН, С NVIDIA СФЕ ЯСЫЕЯРБСЕР ЯОЕЖХЮКХГХПНБЮММНЕ ОПНЦПЮЛЛМН-ЮООЮПЮРМНЕ ПЕЬЕМХЕ Maximus МЮ АЮГЕ БХДЕНЙЮПР Quadro Х Tesla, ОНГБНКЪЧЫЕЕ НДМНБПЕЛЕММН БШОНКМЪРЭ Х ХМФЕМЕПМШИ ЮМЮКХГ Х БХГСЮКХГЮЖХЧ.

нДМНБПЕЛЕММШИ ХМФЕМЕПМШИ ЮМЮКХГ Х ПЕМДЕПХМЦ ДКЪ ЛНРНЖХЙКЮ МЮ ПЮАНВХУ ЯРЮМЖХЪУ NVIDIA Maximus. (хЯРНВМХЙ: NVIDIA)
ю ЙЮЙ ДЕКЮ НАЯРНЪР Я яюоп? йЮГЮКНЯЭ АШ, ЩРХ ОПХКНФЕМХЪ ЯН БПЕЛЕМХ ОНЪБКЕМХЪ ХЯОНКЭГСЧР GPU ОН ОПЪЛНЛС МЮГМЮВЕМХЧ (ПЕМДЕПХМЦ Х БХГСЮКХГЮЖХЪ), Х ХУ ПЮГПЮАНРВХЙХ ДНКФМШ АШРЭ ОПЕЙПЮЯМН НЯБЕДНЛКЕМШ Н БНГЛНФМНЯРЪУ МЕЦПЮТХВЕЯЙХУ БШВХЯКЕМХИ МЮ БХДЕНЙЮПРЮУ.
гДЕЯЭ ЯРНХР ОНЪЯМХРЭ, ВРН НДМНИ ХГ МЮХАНКЕЕ БШВХЯКХРЕКЭМН ЯКНФМШУ ГЮДЮВ Б яюоп ЪБКЪЕРЯЪ ОНЯРПНЕМХЕ Х НАПЮАНРЙЮ РПЕУЛЕПМНИ ЛНДЕКХ, ЙНРНПЮЪ БШОНКМЪЕРЯЪ Я ОНЛНЫЭЧ ЦЕНЛЕРПХВЕЯЙНЦН ЪДПЮ. (аНКЕЕ ОНДПНАМН МЮ РЕЛС ЪДЕП ЛНФМН ОПНВХРЮРЭ Б ЯЕПХХ ЯРЮРЕИ дЛХРПХЪ сЬЮЙНБЮ: «мЮ ЪДПЕ», «цЕНЛЕРПХВЕЯЙХЕ ЪДПЮ Б ЛХПЕ Х Б пНЯЯХХ», «NURBS Х яюоп: 30 КЕР БЛЕЯРЕ».) яНГДЮМХЕ ЛНДЕКХ ХГДЕКХЪ — ЩРН ХМРЕПЮЙРХБМШИ ОПНЖЕЯЯ, Х ХМФЕМЕП МЕ ЛНФЕР ФДЮРЭ ДЕЯЪРНЙ ЯЕЙСМД ДКЪ ГЮБЕПЬЕМХЪ НОПЕДЕКЕММНИ НОЕПЮЖХХ. уНРЪ ОПНХГБНДХРЕКЭМНЯРЭ ЯНБПЕЛЕММШУ ЙНЛЛЕПВЕЯЙХУ ЪДЕП МЮ АНКЭЬХМЯРБЕ ЛНДЕКЕИ БОНКМЕ СДНБКЕРБНПХРЕКЭМЮ, ХГБЕЯРМШ ЯКСВЮХ, ЙНЦДЮ ЯЙНПНЯРЭ НАПЮАНРЙХ МЕНАУНДХЛН СБЕКХВХРЭ Б ЯНРМЧ ПЮГ. рЕУМНКНЦХЪ GPU БШВХЯКЕМХИ ЛНЦКЮ АШ ОПЕДНЯРЮБХРЭ ЩКЕЦЮМРМНЕ ПЕЬЕМХЕ.
3D ЛНДЕКЭ ДЕРЮКХ Б яюоп T-Flex. хЯОНКЭГСЕРЯЪ 3D ЦЕНЛЕРПХВЕЯЙНЕ ЪДПН Parasolid (Siemens PLM Software).
й ЯНФЮКЕМХЧ, МЮ ОПЮЙРХЙЕ БЯ╦ БШЦКЪДХР МЕ РЮЙ НОРХЛХЯРХВМН. б ЯРЮРЭЕ дФНПДФЮ юККЕМЮ (Chief Technologist, Siemens PLM Software), ОПЕДЯРЮБКЕММНИ МЮ ЙНМТЕПЕМЖХХ SIAM Geometric Design and Computing Б 2007 ЦНДС, АШКХ НАНГМЮВЕМШ МЕЯЙНКЭЙН УЮПЮЙРЕПМШУ ОПНАКЕЛ, ОПХЯСЫХУ ЯСЫЕЯРБСЧЫХЛ ЙНЛЛЕПВЕЯЙХЛ ЦЕНЛЕРПХВЕЯЙХЛ ЪДПЮЛ:
- яРПСЙРСПШ ДЮММШУ Х ЮКЦНПХРЛШ ЦЕНЛЕРПХВЕЯЙНЦН ЛНДЕКХПНБЮМХЪ ПЕЮКХГНБЮМШ МЕЩТТЕЙРХБМН ДКЪ ПЮЯОЮПЮККЕКХБЮМХЪ: ОНДПЮГСЛЕБЮЧР ЛМНФЕЯРБН БЕРБЕИ КНЦХЙХ ДКЪ НАПЮАНРЙХ ЯОЕЖХЮКЭМШУ ЯКСВЮЕБ.
- он ПЮГПЮАЮРШБЮКНЯЭ Я ЙНМЖЮ
80-У ЦНДНБ, Х Я РНВЙХ ГПЕМХЪ ЮПУХРЕЙРСПШ МХЙРН МЕ ГЮАНРХКЯЪ Н БНГЛНФМНЛ ПЮЯОЮПЮККЕКХБЮМХХ. пЮГПЮАНРЙЮ ОЮПЮККЕКЭМШУ ЮКЦНПХРЛНБ ОНРПЕАСЕР ОЕПЕОХЯШБЮМХЪ ЛХККХНМНБ ЯРПНЙ legacy-ЙНДЮ Х ТЮЙРХВЕЯЙХ ПЮГПСЬХР ЯОНЯНАМНЯРЭ Й НАЛЕМС ДЮММШЛХ Я ДПСЦХЛХ ЯХЯРЕЛЮЛХ. - лНДХТХЖХПНБЮРЭ ЮКЦНПХРЛШ Б ХМДСЯРПХЮКЭМН ПЮАНРЮЧЫЕЛ ЪДПЕ ВПЕГБШВЮИМН РПСДМН: ОНКЭГНБЮРЕКХ УНРЪР, ВРНАШ ПЕГСКЭРЮРШ НОЕПЮЖХИ Я ЛНДЕКЭЧ АШКХ ОНКМНЯРЭЧ ХДЕМРХВМШ РЕЛ, ЙНРНПШЕ ОНКСВЮКХЯЭ 10 КЕР МЮГЮД.
сВХРШБЮЪ БЯЕ ЩРХ ОПНАКЕЛШ Х РНР ТЮЙР, ВРН ГЮ ОЪРЭ КЕР Я ЛНЛЕМРЮ БШУНДЮ ЩРНИ ЯРЮРЭХ МЕ ОНЪБКЪКНЯЭ МХЙЮЙНИ ХМТНПЛЮЖХХ НА ХЯОНКЭГНБЮМХХ GPU Б ЪДПЮУ ACIS, Parasolid, CGM, Granite One, ЛНФМН ЯДЕКЮРЭ БШБНД, ВРН ЯНАКЮГМХРЕКЭМЮЪ ОЕПЯОЕЙРХБЮ СЯЙНПЕМХЪ яюоп ЛНФЕР ОПНХГНИРХ КХЬЭ Б ПЮЛЙЮУ МЮОХЯЮММНЦН Я МСКЪ ЦЕНЛЕРПХВЕЯЙНЦН ЪДПЮ.
оПХЪРМН НРЛЕРХРЭ, ВРН РЮЙХЕ ПЮАНРШ, БЙКЧВЮЧЫХЕ ЯНГДЮМХЕ ОЮПЮККЕКЭМШУ ЮКЦНПХРЛНБ ДКЪ БШВХЯКЕМХИ Я NURBS ЙПХБШЛХ Х ОНБЕПУМНЯРЪЛХ, НОПЕДЕКЕМХЕЛ ПЮЯЯРНЪМХЪ ЛЕФДС РПЕУЛЕПМШЛХ РЕКЮЛХ Х НАМЮПСФЕМХЕЛ ЯРНКЙМНБЕМХИ, ОНХЯЙНЛ ОЕПЕЯЕВЕМХЪ ОНБЕПУМНЯРЕИ Х ЙПХБШУ, СФЕ ОКНРМН БЕДСРЯЪ ЯХКЮЛХ ПНЯЯХИЯЙХУ ЯОЕЖХЮКХЯРНБ.